前言
此文章用于在阅读labuladong的算法小抄时记录笔记,未来可能也会用于其它算法和数据结构方面学习的笔记
文中示例代码均由
Kotlin编写
第零章 必读
数据结构的存储方式
计算机中,数据结构只有两种:数组(顺序存储)和链表(链式存储)
其它数据结构均是由这两种结构进行组合得来
队列和栈既可以使用数组也可以使用链表来实现,数组需要考虑扩容问题;链表则不用,但需要更多空间存储指针
图也可以用这两种结构来表示,邻接表是链表,邻接矩阵就是而为数组,邻接矩阵判断连通性迅速,但用于存储稀疏图会浪费空间;邻接表比较节省空间,但操作效率比邻接矩阵要低
散列(Hash)表是通过散列函数将键映射到一个大数组里,对于散列冲突,拉链法会通过链表依次存储同散列的键(如 Java 的 HashMap),线性探查法会存到后面的空位上,不需要指针存储空间,但操作稍微复杂
树,用数组实现就是堆,因为堆是一个完全二叉树;用链表实现就是常见的树,不一定是完全二叉树,在基于链表的树的结构之上,又衍生出各种设计,如:二叉搜索树、AVL 树、红黑树、区间树、B 树等等,对应解决不同问题
数组是紧凑连续的存储结构,可以随机访问,且较节约存储空间;但如果内存一次没分配够,需要进行扩容,就需要分配一块更大的空间,将数据全部 copy 过去,时间复杂度 O(N);如果你想在数组中间插入或删除,就必须移动后面的数据以保持连续,时间复杂度也是 O(N)
链表元素并不连续,是靠指针指向下一个元素的位置的,因此不存在扩容问题;如果知道某一个元素的先驱和后驱,操作指针即可删除或插入新元素,时间复杂度 O(1),但正因为存储空间不连续,因此不能随机访问,而且由于需要存储指针,因此会相对消耗更多存储空间
数据结构的基本操作
对任何数据结构,其基本操作无非是遍历 + 访问,具体一点就是增删改查
数据结构种类很多,但他们的目的都是在不同场景下,尽可能高效的进行增删改查
数据访问常见的几种框架:
1 | // 数组遍历结构,典型的线性迭代结构 |
1 | // 链表遍历框架 |
1 | // 二叉树遍历框架,典型的非线性递归遍历结构 |
1 | // N 叉树遍历 |
第一章 动态规划
动态规划问题一般形式就是求最值。动态规划其实是运筹学的一种最优化方法,只不过在计算机问题上应用比较多,比如求最长递增子序列、最小编辑距离等
既然是求最值,核心问题是什么呢?核心问题就是穷举。因为要求最值,就要把所有可行的答案穷举处理啊,然后在其中找最值
动态规划的穷举有些特别,这类问题存在重叠子问题,如果暴力穷举的话效率会很低,所以需要备忘录或DP table来优化穷举过程,避免不必要的计算
另外,虽然动态规划的核心思想就是穷举求最值,但问题可以千变万化,穷举所有可行解并不是一件容易的事,只有列出正确的状态转移方程才能正确的穷举
动态规划详解
斐波那契数列
尽管这个列子严格来说并不是动态规划问题,但可助于理解重叠子问题
暴力递归
斐波那契数列的数学形式递归是这样的:
1 | fun fib(n: Int) = when(n) { |
学校老师讲递归的时候经常会拿这个举例,虽然这样的代码简洁易懂,但十分低效,比如想要计算 f(20),就得先计算 f(19) 和 f(18),然后要计算 f(19),就要先计算 f(18) 和 f(17),以此类推,最后到 f(1) 或 f(2) 时,结果已知,就能直接返回结果,递归树就不再向下生长了
递归算法的时间复杂度怎么计算?子问题个数乘以解决一个子问题需要的时间
子问题个数,显然次问题中为指数级别,子问题个数为 O(2^n)
解决一个子问题需要的时间,由于本算法没有循环,只有一个加法操作,时间为 O(1)
所以这个算法的时间复杂度为 O(2^n),指数级别,爆炸
观察递归流程,很明显可以发现算法低效的原因:存在大量重复计算,如 f(18) 被计算了两次,而且由于 f(18) 的子问题体量巨大,多算一遍会耗费巨大的时间。更何况,还不止 f(18) 这一个问题被重复计算,所以这个算法及其低效
这就是动态规划问题的第一个性质:重叠子问题
带备忘录的递归
既然耗时的原因是重复计算,那么我们可以造一个备忘录,每次算出某个子问题的答案后先记到备忘录里再返回,每次遇到一个子问题先去备忘录查一查,如果发现问题已经被解决过,拿就把答案直接拿出来用,不要再重复计算一次了。
1 | fun fib(n: Int) = fibHelper(IntArray(n), n) // 初始化一个备忘录,转给 helper 方法 |
这样,每个子问题就只会被计算一次,第二次就可以直接从备忘录中获取结果,实际上,带备忘录的递归算法,把一棵存在巨量冗余的递归树通过剪枝,改造成了一副不存在冗余的递归图,极大的减少了子问题的个数
递归算法的时间复杂度怎么计算?子问题个数乘以解决一个子问题需要的时间
子问题个数,由于本算法不存在冗余计算,子问题就是 f(1)、f(2)、f(3) … f(19)、f(20),数量与输入规模 n = 20 成正比,所以子问题个数为 O(n)
解决一个子问题的时间,同上,没什么循环,因此为 O(1)
所以,本算法的时间复杂度为 O(n),对比暴力递归的 O(2^n),简直是降维打击
实际上,这种解法的效率和迭代的动态规划已经差不多了,只不过这种方法叫自顶向下,动态规划叫做自底向上
自顶向下是指从一个规模较大的问题如 f(20) 向下逐渐分解规模,直到 f(1)、f(2) 触底,然后逐层返回答案
自底向上是指,我们从最底下,最简单,问题规模最小的 f(1) 和 f(2) 开始往上推,直到推到我们想要的答案 f(20),这就是动态规划的思路
dp 数组的迭代解法
有了上一步的启发,我们可以把这个备忘录独立出来成为一张表,就叫DP table吧,在这张表上完成自底向上的推算
1 | fun fib(n: Int): Int { |
你会发现这个DP table特别像之前那个剪枝后的结果,只是反过来算而已。实际上,带备忘录的递归解法终端鹅备忘录,最终完成后就是这个DP tabel,所以说这两种解法其实是差不多的,大部分情况下,效率也基本相同
这里,引出状态转移方程这个名词,实际上就是描述问题结构的数学形式:
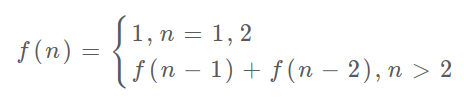
你会发现,上面几种解法的所有操作,例如f(n - 1) + f(n - 2)、dp[i] = dp[i - 1] + dp[i - 2],其实都是围绕这个方程式的不同表现形式,可见列出状态转移方程的重要性,它是解决问题的核心。很容易发现,其实状态转移方程直接代表着暴力解法
千万不要看不起暴力解,动态规划问题最困难的就是列出状态转移方程,即这个暴力解,优化方法无非是用备忘录或DP table,再无奥妙可言
最后,其实根据斐波那契数列的状态转移方程,当前状态只与前两个状态有关,所以其实并不需要那么长的一个DP table来存储所有的状态,只要想办法存储之前的两个状态就行了,所以,可以进一步优化,将空间复杂度降为 O(1)
1 | fun fib(n: Int) = when(n) { |
凑零钱问题
给你
k种面值的硬币,面值分别为c1, c2, ..., ck,每种硬币数量无限,再给一个总金额amount,求出最少需要几枚硬币才能凑出这个金额,如果不能凑出,应返回 -1
首先,这个问题是动态规划问题,因为它具有最优子结构。要符合最优子结构,子问题间必须相互独立,比如,你的原问题是考出最高总成绩,那么你的子问题就是把语文考到最高、数学考到最高… 为了每门课考到最高,你要把每门课的选择题分数拿到最高,填空题分数拿到最高… 当然,最终就是你每门课都是满分,这就是最高的总成绩
最高的总成绩就是总分,这个过程符合最优子结构,每门课考到最高这些子问题是互相独立,互不干扰的
回到凑零钱问题,比如你想求amount = 11时的最少硬币数(原问题),在尝试面值为1的硬币时,只需要将amount = 10的最少硬币数加 1 即可,同理,尝试面值为5的硬币时,只需要将amount = 6的最少硬币数加 1。因为硬币的数量是没有限制的,子问题之间没有相互制衡,是相互独立的
暴力递归
那么,既然这是一个动态规划问题,要如何列出正确的状态转移方程呢?
先确定状态,也就是原问题和子问题中变化的量,由于硬币数量是无限的,所以唯一的状态就是目标金额amount
然后确定dp函数定义:对于目标金额n,至少需要dp(n)个硬币凑出该金额
然后确定选择并择优,也就是对于每个状态,可以作出什么选择来改变当前状态。具体到这个问题,无论当前的目标金额是多少,选择就是从面值列表coins中选择一个硬币,然后目标金额会减少
最后明确base case,显然目标金额为 0 时,所需的硬币数量为 0;当目标金额小于 0 时,无解,返回 -1
1 | fun coinChange(coins: IntArray, amount: Int): Int { |
至此,状态转移方程其实已经完成了,上面的算法已经是暴力解法了,只不过需要消除一下重叠问题
分析一下时间复杂度,子问题个数为O(n ^ k),问题中有一个循环,复杂度为O(k),因此算法的复杂度为O(k * n^k)
带备忘录的递归
只需要稍加修改,就可以通过添加备忘录来消除重叠问题:
1 | fun coinChange(coins: IntArray, amount: Int): Int { |
显然,备忘录大大减少了子问题的数量,完全消除了子问题冗余,所以子问题数量不会超过总金额n,即子问题数量为O(n),处理一个子问题的时间不变,仍然是O(k),因此时间复杂度为O(kn)
dp 数组的迭代解法
通过DP table也可以消除重叠子问题,dp数组和刚刚的dp汉东湖定义类似:
dp[i] = x表示,当目标金额为i时,至少需要x枚硬币
1 | fun coinChange(coins: IntArray, amount: Int): Int { |
此算法的子问题数量和计算一个子问题的复杂度均和上个算法相同,时间复杂度为O(kn)
总结
计算机解决问题其实没有任何奇淫技巧,它唯一的解决方法就是穷举,穷举所有可能性。算法设计无非就是先思考如何穷举,然后再追求如何聪明的穷举
列出状态转移方程,就是在解决如何穷举的问题;备忘录、DP table 就是在追求如何聪明的穷举;用空间换时间的思路,是降低时间复杂度的不二法门
动态规划设计:最长递增子序列
给定一个无序的整数序列,找到其中最长上升子序列的长度。
示例:
1 | 输入: [10, 9, 2, 5, 3, 7, 191, 18] |
动态规划解法
我们设计动态规划算法,需要一个dp数组,那我们可以假设dp[0...i-1]都已经被计算出来了,然后问自己,怎么通过这些结果计算出dp[i]?
直接拿这个例子举例就明白了,不过首先要明确dp数组的含义,这里我们定义:dp[i]表示咦numbers[i]这个数结尾的最长递增子序列长度
举个例子:
| index | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| nums | 1 | 4 | 3 | 4 | 2 | 3 |
| dp | 1 | 2 | 2 | 3 | 2 | ? |
那么我们已经知道dp[0...4]的结果,如何通过这些已知结果推算出dp[5]呢?
这就是动态规划的重头戏了,要思考如何进行状态转移,根据刚才对dp数组的定义,现在想求dp[5]的值,也就是想求以numbers[5]为结尾的最长递增子序列
numbers[5] = 3,既然是递增子序列,只要找前面那些结尾比3小的子序列,然后将3接到最后,就可以形成一个新的递增子序列,而且这个新序列的长度会加一
当然,可能会存在很多子序列,但我们只对最长的感兴趣,找到最长的长度加一后作为dp[5]的值即可
1 | fun lengthOfLIS(numbers: IntArray): Int { |
至此,这道题就解决了,时间复杂度为O(N^2),总结下动态规划的设计流程:
首先明确dp数组所存数据的含义,这点很重要,如果不得当或不清晰,会阻碍后续的步骤
然后根据dp数组的定义,假设dp[0...i-1]都已知,想办法求出dp[i],一旦这一步完成,整个题目就基本解决了
如果无法完成这一步,就可能是dp数组定义的不够恰当,需要重新定义dp数组的含义;也可能是dp数组中存储的信息还不够,不足以推导出下一步的答案